Lineagentic-KG: Turn YAML into a Knowledge Graph in minutes
By Ali Shamsaddinlou
Lineagentic-KG: Turn YAML into a Knowledge Graph in minutes
Introduction
Modern enterprises depend on accurate, discoverable, and governed data to power analytics and AI initiatives. But setting up and maintaining a robust data catalog often requires stitching together multiple tools, writing custom APIs, and managing separate governance systems.
Lineagentic-KG changes that equation. It's a graph-native, YAML-driven application that automatically generates a full-featured knowledge graph—complete with REST APIs, CLI tooling, customizable taxonomies, and federated governance—all out-of-the-box.
YAML-First Philosophy
At its core, Lineagentic-KG relies on a simple YAML configuration to describe assets, schemas, lineage, and governance rules. From this single file, the system spins up a fully operational knowledge graph.
Example YAML snippet:
assets: - name: sales.orders type: table description: "Customer orders dataset" schema: - name: order_id type: integer - name: customer_id type: integer - name: amount type: decimal taxonomy: domain: Finance sensitivity: Confidential lineage: upstream: - source: sales.raw_orders downstream: - layer: analytics.orders_summary
Graph-Native Foundation
Unlike traditional relational metadata stores, Lineagentic-KG is built around a graph model.
- Lineage as a graph: Upstream and downstream dependencies are first-class citizens.
- Extensibility: New node types (e.g., ML models, dashboards, pipelines) can be added without re-architecting.
- Flexible queries: Graph traversal makes it easy to answer questions like "Which downstream assets are impacted if this table changes?" or "Show all datasets linked to Customer PII."
This graph foundation makes the catalog highly customizable and inherently suited for federated governance.
System Architecture & Flow
Lineagentic-KG operates through a sophisticated architecture that handles both bootstrap and runtime phases. Here's how the system works:
Bootstrap Phase: RegistryFactory Initialization
The system starts by loading YAML configuration, validating it, and generating the necessary classes and methods dynamically.
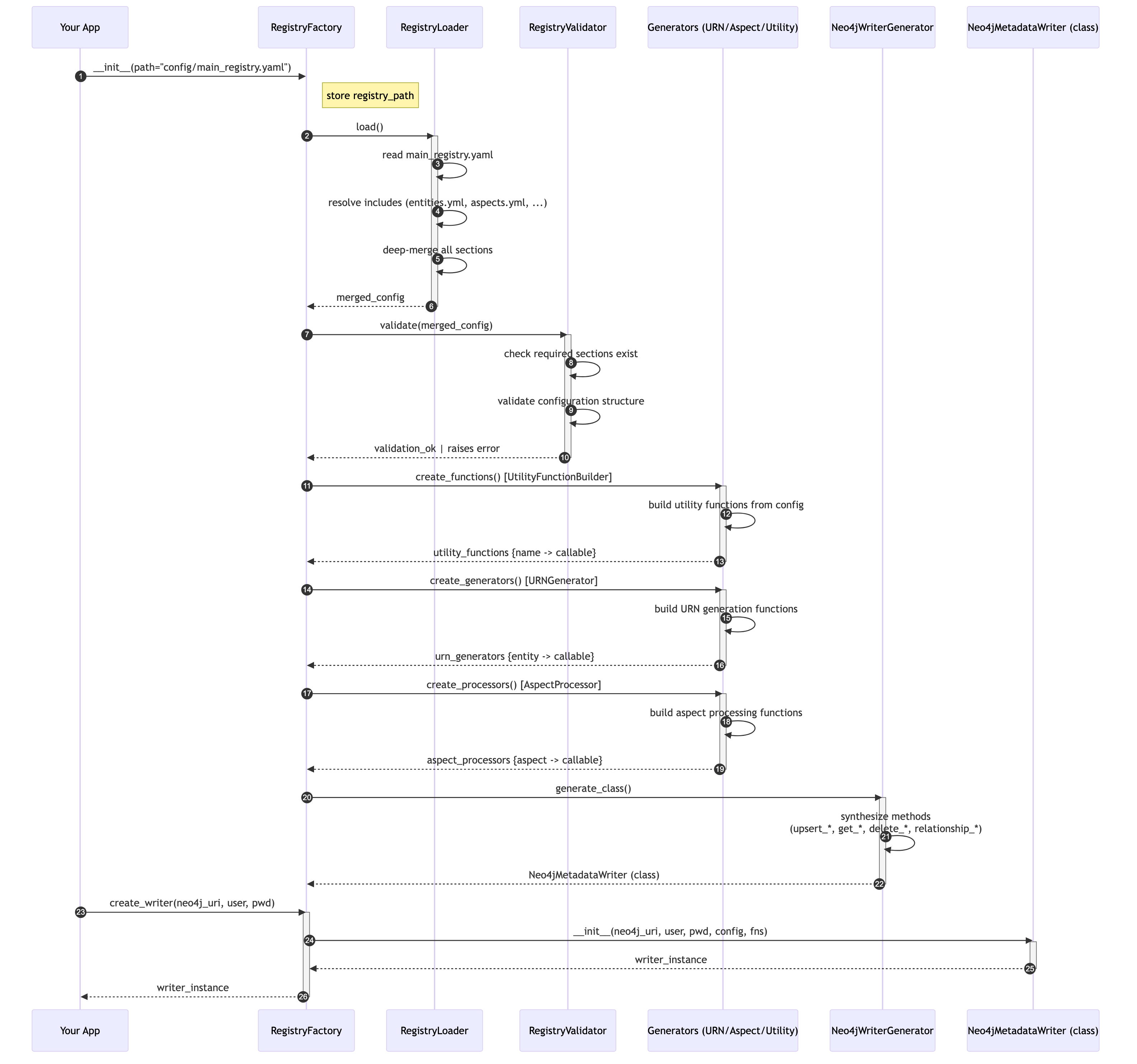
Shows how RegistryFactory loads config, validates it, generates functions, and creates the final writer class
Runtime Phase: Using Generated Methods
Once initialized, the system provides a seamless runtime experience where generated methods handle URN generation, database operations, and aspect processing.
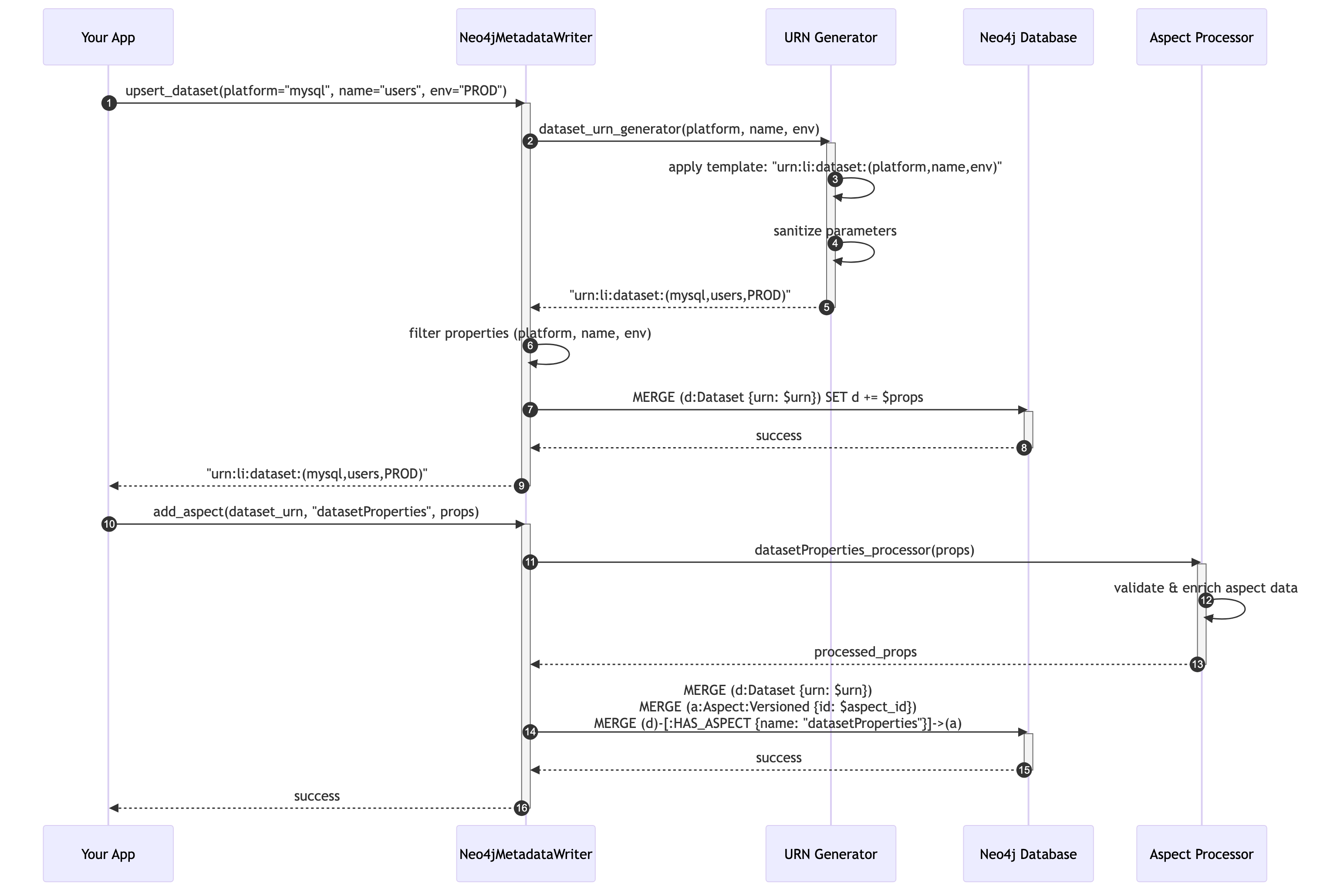
Shows the flow when calling upsert_dataset() and add_aspect() methods
Configuration Loading Flow
The system intelligently merges multiple YAML files using an include mechanism and deep merging process.
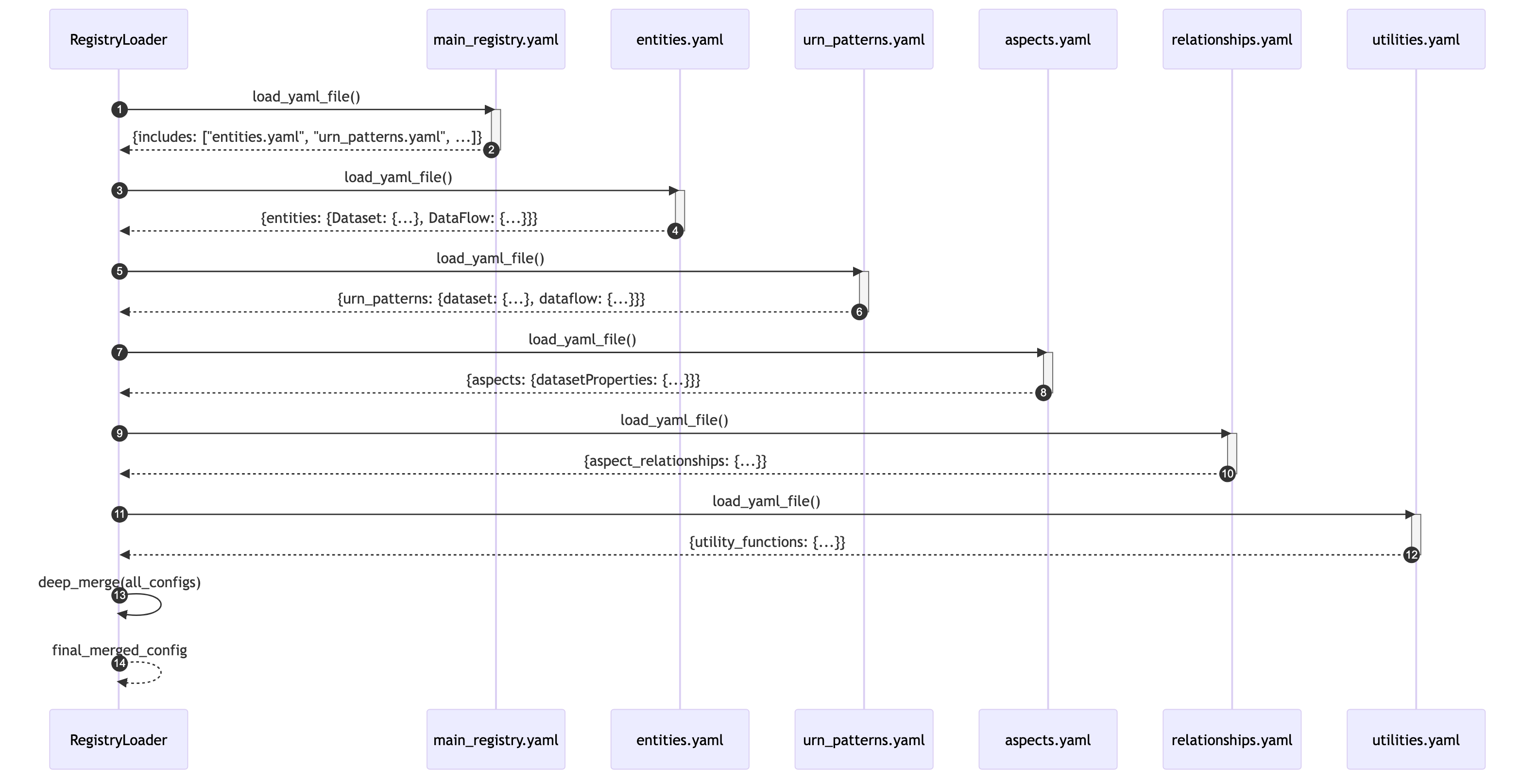
Shows how RegistryLoader merges multiple YAML files into one configuration
Method Generation Flow
Dynamic method creation from configuration allows the system to generate upsert_*, get_*, and delete_* methods for each entity automatically.
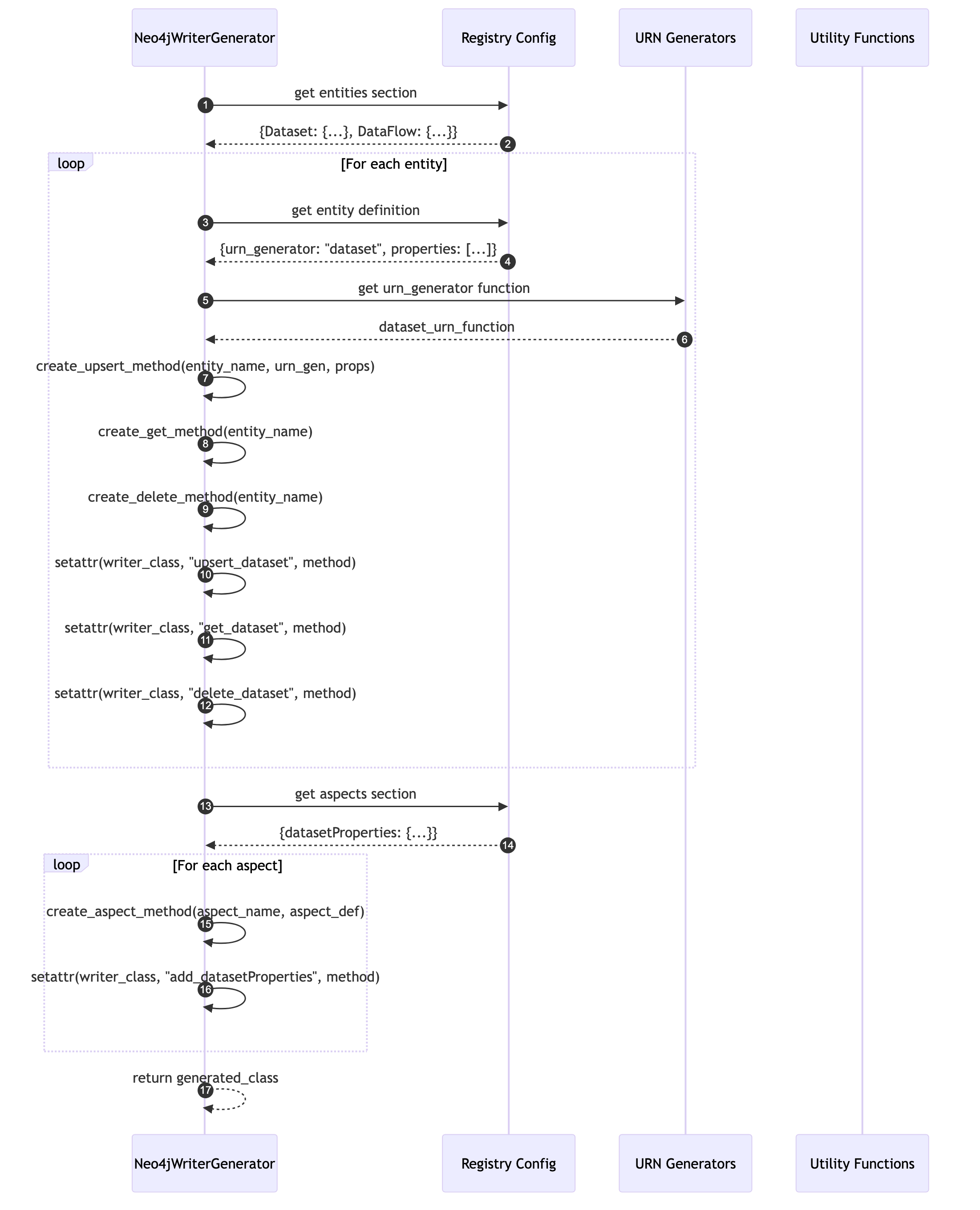
Shows how Neo4jWriterGenerator creates upsert_*, get_*, and delete_* methods dynamically
Overall System Architecture
The complete system architecture shows how all components interact to provide a unified data catalog experience.
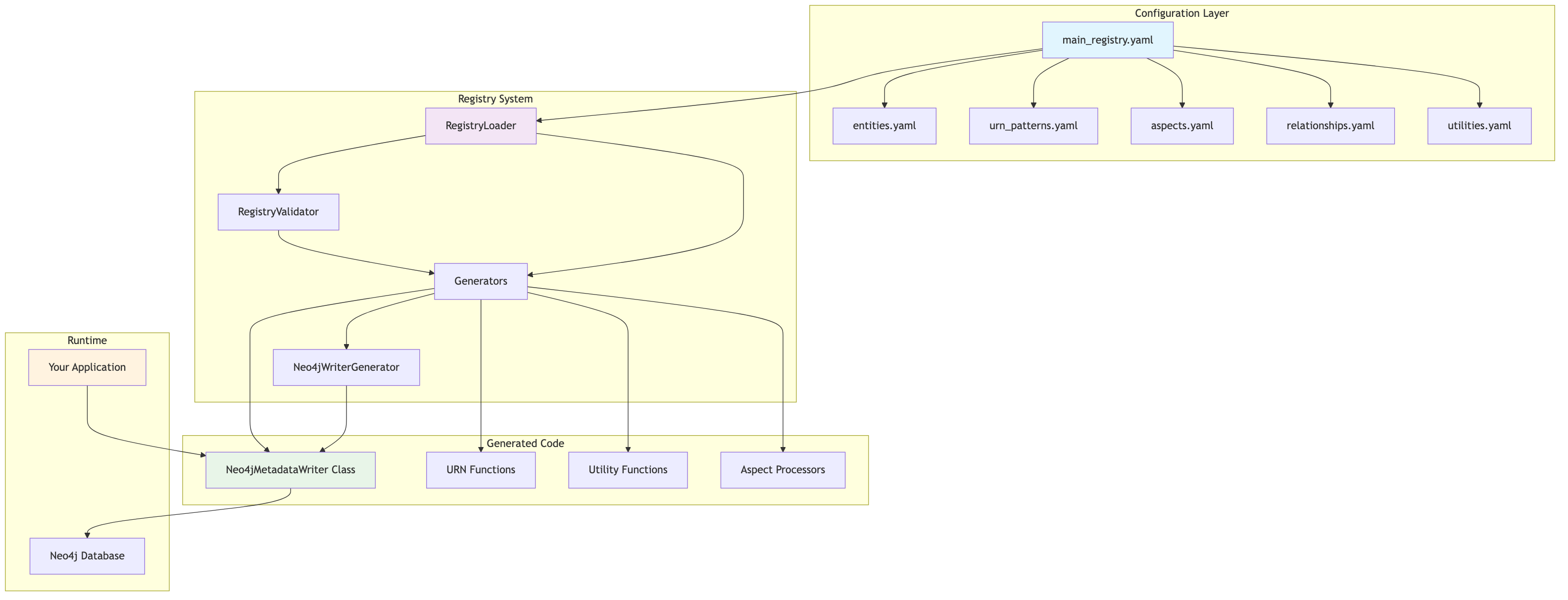
High-level view of the complete registry system architecture
Data Flow Overview
The overall data flow demonstrates how information moves from configuration files to database operations seamlessly.

Simplified view of how data flows through the system
Batteries Included
Lineagentic-KG comes with everything needed to be productive immediately:
REST API
GET /assets– list all assetsGET /assets/{name}– get details and schemaGET /lineage/{name}– fetch full lineage graph- Auto-generated OpenAPI/Swagger docs
CLI Tooling
lineagentic list– show all registered assetslineagentic describe sales.orders– view schema, lineage, and taxonomylineagentic lineage sales.orders– visualize dependencies
Storage & Indexing
- Graph database backend for lineage and taxonomy
- Embedded search for fast discovery
Custom Taxonomy & Data Model
Every organization has its own way of classifying and governing data. Lineagentic-KG supports:
- Custom taxonomies (domains, sensitivity levels, lifecycle states, etc.)
- Flexible data models: Add your own asset types (datasets, APIs, ML features, reports)
- Schema evolution: Versioning and change history are built in
This ensures the catalog adapts to your enterprise vocabulary instead of forcing you into a rigid model.
Federated Governance
Because the underlying model is graph-based and generic, governance can be federated across teams and domains:
- Decentralized ownership – Teams manage their own YAML definitions, version-controlled in Git.
- Central visibility – The graph model unifies these definitions into one enterprise-wide catalog.
- Policy hooks – Governance rules (access control, classification, retention) can be defined once and enforced everywhere.
This aligns with data mesh principles, giving both autonomy and oversight.
Why Lineagentic-KG Matters
- Declarative & version-controlled – YAML as the single source of truth
- Graph-native – naturally models relationships, lineage, and governance
- All-in-one – REST, CLI, storage, and APIs provided automatically
- Extensible – customize taxonomy, add new data models, and extend governance easily
- Federated by design – supports decentralized ownership with centralized policies
Conclusion
Lineagentic-KG is a code-first knowledge graph platform that turns simple YAML definitions into a fully operational, customizable, and governed data ecosystem. With REST APIs, CLI tooling, federated governance, and extensibility built in, it delivers a "batteries included" experience for modern data teams.
By uniting declarative configuration, graph flexibility, and governance controls, Lineagentic-KG helps organizations scale their data culture without scaling complexity.